Don't get me wrong, the addition of Git to TFS is huge, and it actually removes all of my previous complains about the platform. Sadly, the API's for it aren't up to par yet, the documentation is poor, and the technology is so young that the Internet is completely silent on how to programmatically accomplish just about anything with it.
![]()
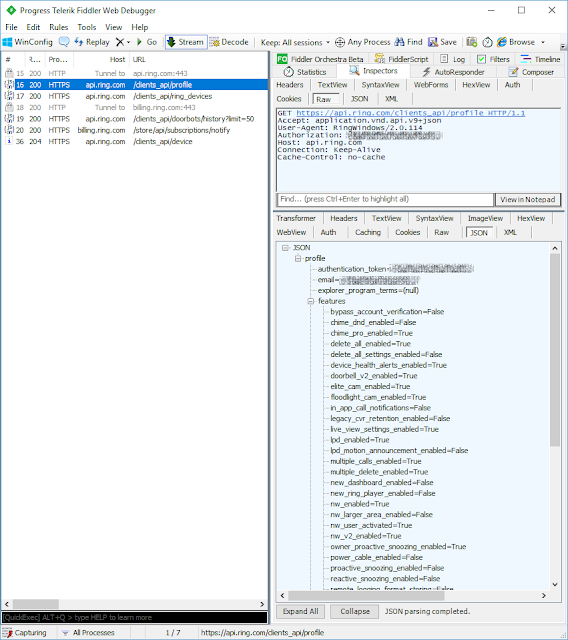
So after about 24 total hours of wasting time searching the internet, decompiling source, watching network traffic on Fiddler, and triggering builds I have some working code (and a bit of a rant) that I wanted to share to help fill out the Internet (because clearly it doesn't contain enough ranting; but at least this one has working code).
As my regular readers no doubt know I occupy my spare time running Siren of Shame, a build monitor, USB siren, and CI gamification engine. The software needs to work such that when a continuous integration build is triggered it needs to determine which check-in triggered the build and give that user credit for the check-in (or exude a little light hearted shame on failure).
For every other major CI server in the world this is pretty easy. TFS 2013 + Git? Not so much. If it worked the way it should you could simply do this:
var buildQueryResult = _buildServer.QueryBuilds(query);
var buildDetail = buildQueryResult.Builds[0];
var commits = buildDetail.Information.GetNodesByType("AssociatedCommit");
And it wouldn't even require a second web request to get the triggering commit.
Sadly, the above only works for completed builds. In-progress builds return nothing in AssociatedCommit().
That's the older, strongly typed API that requires referencing Microsoft.TeamFoundation.Build.Client.dll (which you can find in the GAC). With TFS 2013, there is now also a TFS Web API. Sadly even the equivalent new Web API methods have the same limitation. For example if build 5 were in progress then this:
GET http://myserver:8080/defaultcollection/project/_apis/build/builds/5/details?api-version=1.0&types=AssociatedCommit&types=AssociatedChangeset
Wouldn't return the associated commit until it completed.
So, for in-progress builds you're stuck doing a second query.
Ideally at this point you would use the powerful and convenient QueryHistory() method. Using it looks something like this:
Sadly this only works for changesets; in other words traditional Team Foundation Version Control (TFVC) checkins. It doesn't work for Git, despite that what we want to accomplish is so very, very similar (i.e. couldn't we just throw in an overload that asks for the branch you're querying against?).
As far as I can tell there is only one remaining option. It's the new TFS Rest API.
There are two ways to use it. The documentation says to use an HttpClient, but there's also a nice convenience wrapper that you can get by adding a reference to Microsoft.TeamFoundation.SourceControl.WebApi.dll, which you can find in the GAC. Using this approach if you write something like this:
I've documented everything I hate about this in comments, but the most important point is this: The workspace mapping API for build definitions (which says which folder(s) trigger the build) fails to include a branch property. This is true even for the Web API's. For instance:
http://tfsserver:8080/tfs/DefaultCollection/_apis/build/definitions/1?api=1.0
Fails to tell us anything about the workspace mappings. This API omission forces you to query all branches, which requests lots of web requests. Specifically it requires the number of pushed branches plus two web requests in order to find the latest check-in across all branches. This could be insanely expensive, and it might not even be correct in some circumstances.
As nice as the strongly typed API approach sounds, it turns out to be missing a number of API's that you can get to if you use a WebClient to request them manually. Specifically if you use the web API directly you can issue a single request against the commits endpoint to get the latest commit across all branches.
Sadly, the authentication via WebClient is a bit tricky and is dependent upon whether you are using a locally hosted TFS or Visual Studio Online. For this reason you're better off with some helper methods:
Is this absolutely terrible? Perhaps not But it is a lot of code to do something that used to be quite simple with TFVC and is quite simple with all other build servers (or at least those I have experience with, specifically: Hudson, Jenkins, Team City, Bamboo, CruiseControl, and Travis).

So after about 24 total hours of wasting time searching the internet, decompiling source, watching network traffic on Fiddler, and triggering builds I have some working code (and a bit of a rant) that I wanted to share to help fill out the Internet (because clearly it doesn't contain enough ranting; but at least this one has working code).
API #Fail
As my regular readers no doubt know I occupy my spare time running Siren of Shame, a build monitor, USB siren, and CI gamification engine. The software needs to work such that when a continuous integration build is triggered it needs to determine which check-in triggered the build and give that user credit for the check-in (or exude a little light hearted shame on failure).
For every other major CI server in the world this is pretty easy. TFS 2013 + Git? Not so much. If it worked the way it should you could simply do this:
var query = _buildServer.CreateBuildDetailSpec(buildDefinitionUris);
query.MaxBuildsPerDefinition = 1;
query.Status = Microsoft.TeamFoundation.Build.Client.BuildStatus.All;
query.QueryOrder = BuildQueryOrder.FinishTimeDescending;
// this gets changesets (TFVC) as well as commits (Git)
query.InformationTypes = new[] { "AssociatedChangeset", "AssociatedCommit" };
query.InformationTypes = new[] { "AssociatedChangeset", "AssociatedCommit" };
var buildQueryResult = _buildServer.QueryBuilds(query);
var buildDetail = buildQueryResult.Builds[0];
var commits = buildDetail.Information.GetNodesByType("AssociatedCommit");
Sadly, the above only works for completed builds. In-progress builds return nothing in AssociatedCommit().
That's the older, strongly typed API that requires referencing Microsoft.TeamFoundation.Build.Client.dll (which you can find in the GAC). With TFS 2013, there is now also a TFS Web API. Sadly even the equivalent new Web API methods have the same limitation. For example if build 5 were in progress then this:
GET http://myserver:8080/defaultcollection/project/_apis/build/builds/5/details?api-version=1.0&types=AssociatedCommit&types=AssociatedChangeset
Wouldn't return the associated commit until it completed.
So, for in-progress builds you're stuck doing a second query.
More API #Fail
Ideally at this point you would use the powerful and convenient QueryHistory() method. Using it looks something like this:
var workspaceServerMappings = _buildDefinition.Workspace.Mappings
.Where(m => m.MappingType != WorkspaceMappingType.Cloak)
.Select(m => m.ServerItem);
var workspaceMappingServerUrl = workspaceMappingServerMappings[0];
// p.s. GetService() is a dumb way to get services, why not just make
// it dynamic, it’s just as undiscoverable
var versionControlServer = _tfsTeamProjectCollection.GetService<VersionControlServer>();
// notice the workspace server mapping url is a parameter. This facilitates onne web call
var changesets = versionControlServer.QueryHistory(workspaceMappingServerUrl,
// p.s. GetService
// it dynamic, it’s just as undiscoverable
var versionControlServer = _tfsTeamProjectCollection.GetService<VersionControlServer>();
// notice the workspace server mapping url is a parameter. This facilitates onne web call
var changesets = versionControlServer.QueryHistory(workspaceMappingServerUrl,
version: VersionSpec.Latest,
deletionId: 0,
recursion: RecursionType.Full,
user: null,
versionFrom: null,
versionTo: VersionSpec.Latest,
maxCount: 1,
includeChanges: true,
slotMode: false,
includeDownloadInfo: true);
Sadly this only works for changesets; in other words traditional Team Foundation Version Control (TFVC) checkins. It doesn't work for Git, despite that what we want to accomplish is so very, very similar (i.e. couldn't we just throw in an overload that asks for the branch you're querying against?).
But Wait, There's More
As far as I can tell there is only one remaining option. It's the new TFS Rest API.
There are two ways to use it. The documentation says to use an HttpClient, but there's also a nice convenience wrapper that you can get by adding a reference to Microsoft.TeamFoundation.SourceControl.WebApi.dll, which you can find in the GAC. Using this approach if you write something like this:
var vssCredentials = newVssCredentials(newWindowsCredential(_networkCredential));
GitHttpClient client = newGitHttpClient(projectCollectionUri, vssCredentials)
GitHttpClient client = newGitHttpClient(projectCollectionUri, vssCredentials)
// unnecessary web request #1: get the list of all repositories to get our repository id (guid)
var repositories = await client.GetRepositoriesAsync();
// sadly the workspace server mapping in the build definition barely resembles the repository Name, thus the EndsWith()
var repository = repositories.FirstOrDefault(i => workspaceMappingServerUrl.EndsWith(i.Name));
// sadly the workspace server mapping in the build definition barely resembles the repository Name, thus the EndsWith()
var repository = repositories.FirstOrDefault(i => workspaceMappingServerUrl.EndsWith(i.Name));
var repositoryId = repository.Id;
// unnecessary web request #2: the workspace server mapping told us which server path triggered the build, but it #FAIL’ed to tell us which branch, so we have to scan them all!!!
var branches = await client.GetBranchRefsAsync(repositoryId);
List<GitCommitRef> latestCommitForEachBranch = newList<GitCommitRef>();
// unnecessary web request #2: the workspace server mapping told us which server path triggered the build, but it #FAIL’ed to tell us which branch, so we have to scan them all!!!
var branches = await client.GetBranchRefsAsync(repositoryId);
List<GitCommitRef> latestCommitForEachBranch = newList<GitCommitRef>();
foreach (var branchRef in branches)
{
// branchRef.Name = e.g. 'refs/heads/master', but GetBranchStatisticsAsync() needs just 'master'
var branchName = branchRef.Name.Split('/').Last();
// Ack! Unnecessary web requests #3 through (number of branches + 2)!!!
// p.s. repositoryId.ToString()? Can we please be consistent with data types!?
var gitBranchStats = await client.GetBranchStatisticsAsync(repositoryId.ToString(), branchName);
// p.s. repositoryId.ToString()? Can we please be consistent with data types!?
var gitBranchStats = await client.GetBranchStatisticsAsync(repositoryId.ToString(), branchName);
latestCommitForEachBranch.Add(gitBranchStats.Commit);
}
var lastCheckinAcrossAllBranches = latestCommitForEachBranch.Aggregate((i, j) => i.Author.Date > j.Author.Date ? i : j);
I've documented everything I hate about this in comments, but the most important point is this: The workspace mapping API for build definitions (which says which folder(s) trigger the build) fails to include a branch property. This is true even for the Web API's. For instance:
http://tfsserver:8080/tfs/DefaultCollection/_apis/build/definitions/1?api=1.0
Fails to tell us anything about the workspace mappings. This API omission forces you to query all branches, which requests lots of web requests. Specifically it requires the number of pushed branches plus two web requests in order to find the latest check-in across all branches. This could be insanely expensive, and it might not even be correct in some circumstances.
Is There No Better Way?
As nice as the strongly typed API approach sounds, it turns out to be missing a number of API's that you can get to if you use a WebClient to request them manually. Specifically if you use the web API directly you can issue a single request against the commits endpoint to get the latest commit across all branches.
Sadly, the authentication via WebClient is a bit tricky and is dependent upon whether you are using a locally hosted TFS or Visual Studio Online. For this reason you're better off with some helper methods:
///
/// This method handles requests to the TFS api + authentication
///
publicasyncTask ExecuteGetHttpClientRequest( string relativeUrl, Func<dynamic, T> action)
{
using (var webClient = GetRestWebClient())
{
string fullUrl = Uri + relativeUrl;
var resultString = await webClient.DownloadStringTaskAsync(fullUrl);
dynamic deserializedResult = JsonConvert.DeserializeObject(resultString);
return action(deserializedResult.value);
}
}
publicWebClient GetRestWebClient()
{
var webClient = newWebClient();
if (MyTfsServer.IsHostedTfs)
{
SetBasicAuthCredentials(webClient);
}
else
{
SetNetworkCredentials(webClient);
}
webClient.Headers.Add(HttpRequestHeader.ContentType, "application/json; charset=utf-8");
return webClient;
}
///
/// Using basic auth via network headers should be unnecessary, but with hosted TFS the NetworkCredential method
/// just doesn't work. Watch it in Fiddler and it just isn't adding the Authentication header at all.
///
///
privatevoid SetBasicAuthCredentials(WebClient webClient)
{
var authenticationHeader = GetBasicAuthHeader();
webClient.Headers.Add(authenticationHeader);
}
publicNameValueCollection GetBasicAuthHeader()
{
conststring userName = "username";
conststring password = "password";
string usernamePassword = Convert.ToBase64String(System.Text.Encoding.ASCII.GetBytes(string.Format("{0}:{1}", userName, password)));
returnnewNameValueCollection
{
{"Authorization", "basic" + usernamePassword}
};
}
privatevoid SetNetworkCredentials(WebClient webClient)
{
var networkCredentials = newNetworkCredential("username", "password");
webClient.UseDefaultCredentials = networkCredentials == null;
if (networkCredentials != null)
{
webClient.Credentials = networkCredentials;
}
}
Wow. That's a lot of boilerplate setup code. Now to actually use it to retrieve check-in information associated with a build:
// Get all repositories so we can find the id of the one that matches our workspace server mapping
var repositoryId = await _myTfsProject.ProjectCollection.ExecuteGetHttpClientRequest<Guid?>("/_apis/git/repositories", repositories =>
{
foreach (var workspaceMappingServerUrl in workspaceMappingServerUrls)
{
foreach (var repository in repositories)
{
string repositoryName = repository.name;
if (workspaceMappingServerUrl.EndsWith(repositoryName))
{
return repository.id;
}
}
}
returnnull;
});
// now get commits for the repository id we just retrieved. This will get the most recent across all branches, which is usually good enough
var getCommitsUrl = "/_apis/git/repositories/" + repositoryId + "/commits?top=1";
var commit = await _myTfsProject.ProjectCollection.ExecuteGetHttpClientRequest(getCommitsUrl, commits =>
{
var comment = commits[0].comment;
var author = commits[0].author.name;
returnnewCheckinInfo
{
Comment = comment,
Committer = author
};
});
return commit;Summary
So that's my story and I'm sticking to it. If any readers find a better approach please post in the comments, send me a note at @lprichar, issue a pull request against my CheckinInfoGetterService.cs where you can find the full source for this article, and/or comment on this SO article where I originally started this terrible journey. Hopefully this will save someone else some time -- if not in the solution, perhaps in the following advice: if you value your time avoid the TFS Git API.






















 Lee Richardson is a senior software developer at
Lee Richardson is a senior software developer at